
前言
二十多天前,我在在Coursera上学完Andrew Ng(吴恩达)老师的机器学习课程。为了避免知识遗忘,重新捋了一遍课程PPT、他人的笔记等,将一些知识点摘抄下来,作为我的知识总结。
吴恩达老师的课程主要包括三个部分:
- 监督学习
- 非监督学习
- 经验以及其它
我的总结也按照这样分类。这篇是第一篇,主要总结监督学习的有关内容。
其他两篇的链接如下:
另外,需要说明的是,由于博客暂时不能支持markdown的数学公式。暂时,你也可以选择在Github仓库中查看: )
机器学习的分类
监督式学习: 给定数据集并且知道其标签(正确的输出),分为:
- 回归 (Regressioin): 输出连续
- 分类 (Classification):输出离散
非监督式学习: 给定数据集,没有标签,分为:
- 聚类(Clustering): Examples: Google News, Computer Clustering, Markert Segmentation.
- 关联(Associative):Examples: 根据病人特征估算其病症.
回归
一元线性回归
假设(Hypothesis):
$$
h_θ(x)=θ_0+θ_1x
$$
参数(Parameters):
$$
θ_0,θ_1
$$
代价函数(Cost Function):
$$
J(θ_0,θ1)=\frac{1}{2m}∑{i=1}^{m}(hθ(x^{(i)})−y^{(i)})^2
$$
目标函数(Goal):
$$
min{θ0,θ1}J(θ_0,θ_1)
$$
一元线性回归的学习目标就是使得代价函数最小。
梯度下降算法(Gradient Descent)
梯度下降算法是通过不断迭代求最小值的方法,它不仅用于线性回归,还可以用于其他算法。
基本步骤如下:
- 初始化$\theta_0, \theta_1$
- 调整$\theta_0, \theta_1$直到$J(\theta_0, \theta_1)$达到最小值, 更新公式$\theta_j = \theta_j - \alpha\frac{\partial}{\partial \theta_j}J(\theta_0, \theta_1)$
对于一元线性回归方程(推导过程省略)
$$
\frac{\partial }{\partial \theta_0} J(\theta_0, \theta1) =\frac{1}{m} \sum{i=0}^{m} \left( (h(x^{(i)}) – y^{(i)}) \right)
$$
$$
\frac{\partial }{\partial \theta_0} J(\theta_0, \theta1) = \frac{1}{m} \sum{i=0}^{m} \left( (h(x^{(i)}) – y^{(i)}) \cdot x\right)
$$
从而参数$\theta_0, \theta_1$的更新公式为
$$
\theta_0 := \theta0 -\alpha \frac{1}{m} \sum{i=0}^{m} \left( (h(x^{(i)}) – y^{(i)}) \right)
$$
$$
\theta_1 := \theta1 -\alpha \frac{1}{m} \sum{i=0}^{m} \left( (h(x^{(i)}) – y^{(i)}) \cdot x\right)
$$
其中α称为学习速率(learning rate),如果其太小,则算法收敛速度太慢;反之,如果太大,则算法可能会错过最小值,甚至不收敛。
另一个需要注意的问题是,上面$\theta_0, \theta_1$的更新公式用到了数据集的全部数据 (称为“Batch” Gradient Descent),这意味着对于每一次 update ,我们必须扫描整个数据集,会导致更新速度过慢。
多元线性回归
假设 (Hypothesis):
$$
h_\theta(x)=\theta^Tx=\theta_0x_0+\theta_1x_1+\ldots+\theta_nx_n
$$
参数 (Parameters):
$$
\theta_0, \theta_1, \ldots, \theta_n
$$
代价函数 (Cost function):
$$
J(\theta_0, \theta_1, \ldots, \thetan)=\frac{1}{2m}\sum\limits{i=1}^{m}(h\theta(x^{(i)}) - y^{(i)})^2
$$
目标 (Goal):
$$
\min\theta J(\theta)
$$
梯度下降算法
梯度下降更新规则(j分别从0到n为一次迭代):
$$
\theta_j := \theta_j – \alpha \frac{\partial }{\partial \theta_j} J(\theta_0, \theta_1, …, \theta_n)
$$
结果:
$$
\theta_j := \thetaj -\alpha \frac{1}{m} \sum{i=0}^{m} \left( (h(x^{(i)}) – y^{(i)}) \cdot x_j\right)
$$
特征缩放
特征缩放是为了收敛地更快。
多特征的时候,如果特征之间的范围不一致,比如x1的范围是0-1,x2的范围却是0-99999 。这样会导致收敛很慢。
$$
x_n = \frac{x_n – \mu_n}{s_n}
$$
$μ$是所有样本的平均值,$s_n$是所有样本的范围差,就是样本中最大的数值减去样本中的最小值。
学习率
学习率太小,收敛很慢。学习率太大,$J(\theta)$可能不降反升。
Normal Equation
该方法不需要和梯度下降算法一样迭代,而是通过数学方法直接求出令J最小的参数值。
$$
\theta = (x^Tx)^{-1} x^T y
$$
具体推导点击这里
Normal Equation的优势是不需要迭代,不需要选择学习率。其缺点是n非常大时,计算速度非常慢,因为要计算一个非常大的矩阵的逆。
分类
逻辑回归(Logistic Regression)
逻辑回归虽然带有“回归”两个字,实际上却是分类问题,此时要预测的值y是离散的。例如判断一封邮件是否是垃圾邮件,判断肿瘤是恶性还是良性。
假设 (Hypothesis):
$$
h_\theta(x) = g(\theta^Tx)
$$
$$
g(z) = \frac{1}{1+e^{-z}}
$$
其中g(z)称为sigmoid函数,其函数图象如下图所示。对于$h\theta(x) \geq 0.5$,模型输出 y=1;对于$h\theta(x) < 0.5$ ,y=0。

代价函数(Cost Function)
逻辑回归中,h(x)的形式变了。如果沿用线性回归的代价公式,将导致J是一个非凸函数,不利于我们找最值。
需要重新定义:
$$
J(\theta) = \frac{1}{m} \sum_{i = 1}^{m} \left( Cost(h(x^{(i)}), y^{(i)})\right)
$$
$$
Cost(h(x), y) = \begin{cases}
-log(h(x)), & \text{if $y$ = 1} \
-log(1-h(x)), & \text{if $y$ = 0} \
\end{cases}
$$
h(x)和Cost(h(x), y)之间的关系如下:

Cost可以合并一种
$$
Cost(h(x), y) = -y log(h(x)) – (1-y) log(1-h(x))
$$
带入到代价函数中
$$
J(\theta) = – \frac{1}{m} \sum_{i = 1}^{m} \left( y^{(i)} log(h(x^{(i)})) + (1-y^{(i)}) log\left(1-h(x^{(i)})\right) \right)
$$
注意这里的负号
目标 (Goal):
$$
\min_\theta J(\theta)
$$
梯度下降算法
直接给出结果
$$
\theta_j := \thetaj – \frac{\alpha}{m} \sum{i=1}^{m}\left( \left(h(x^{(i)}) – y^{(i)}\right) x_j^{(i)} \right)
$$
推导点这里
高级优化算法
除了梯度下降算法,可以采用高级优化算法,比如下面的集中,这些算法优点是不需要手动选择α,比梯度下降算法更快;缺点是算法更加复杂。
- 共轭梯度法(conjugate gradient)
- 局部优化法(Broyden fletcher goldfarb shann,BFGS)
- 有限内存局部优化法L-BFGS(对BFGS的一种改进)
过拟合(Overfitting)

右边使用最复杂的模型所有的数据都在回归曲线上,表面上看能够很好的吻合数据,然而当对新的example预测时,并不能很好的表现其趋势,称为过拟合(overfitting)。
解决方案:
- 减少特征数量:
- 人工选择重要特征,丢弃不必要的特征
- 利用算法进行选择(PCA算法等)
- 正则化Regularization
- 保持特征的数量不变,但是减少参数$\theta_j$的数量级或者值
- 这种方法对于有许多特征,并且每种特征对于结果的贡献都比较小时,非常有效
正则化(Regularization)
线性回归的Regularization
在原来的代价函数中加入参数惩罚项如下式所示,注意惩罚项从$j=1$开始,第0个特征是全1向量,不需要惩罚。
代价函数:
$$
J(\theta) = \frac{1}{2m}\left[ \sum\limits{i=1}^{m} (h\theta(x^{(i)})-y^{(i)})^2 + \lambda \sum\limits_{j=1}^{n}\theta_j^{2}\right]
$$
梯度下降参数更新:
$$
\theta_0 = \theta0 - \alpha\frac{1}{m}\sum\limits{i=1}^{m}(h_\theta(x^{(i)})-y^{(i)})x_0^{(i)}; j = 0
$$
$$
\theta_j = \thetaj - \alpha \left[ \frac{1}{m}\sum\limits{i=1}^{m}(h_\theta(x^{(i)})-y^{(i)})x_j^{(i)} + \frac{\lambda}{m}\theta_j \right]; j > 1
$$
Logistic回归的Regularization
代价函数:
$$
J(\theta) = -\frac{1}{m} \sum\limits{i=1}^{m}\left[y^{(i)}\log(h\theta(x^{(i)})) +(1-y^{(i)})\log(1-h\theta(x^{(i)}))\right] + \frac{\lambda}{2m}\sum\limits{j=1}^{n}\theta_j^{2}
$$
梯度下降参数更新:
$$
\theta_0 = \theta0 - \alpha\frac{1}{m}\sum\limits{i=1}^{m}(h_\theta(x^{(i)})-y^{(i)})x_0^{(i)}; j = 0
$$
$$
\theta_j = \thetaj - \alpha \left[ \frac{1}{m}\sum\limits{i=1}^{m}(h_\theta(x^{(i)})-y^{(i)})x_j^{(i)} + \frac{\lambda}{m}\theta_j \right]; j > 1
$$
神经网络(Neural Network)
为什么要用神经网络?
对于非线性分类问题,如果用多元线性回归进行分类,需要构造许多高次项,导致特征特多学习参数过多,从而复杂度太高。
模型表示
一个简单的神经网络如下图所示,每一个圆圈表示一个神经元,每个神经元接收上一层神经元的输出作为其输入,同时其输出信号到下一层,其中每一层的第一个神经元称为bias unit,它是额外加入的其值为1,通常用+1表示,下图用虚线画出。

符号说明:
- $a_i^{(j)}$表示第j层网络的第i个神经元,例如下图$a_1^{(2)}$就表示第二层的第一个神经元
- $\theta^{(j)}$表示从第j层到第j+1层的权重矩阵,例如下图所有的$\theta^{(1)}$表示从第一层到第二层的权重矩阵
- $\theta^{(j)}{uv}$表示从第j层的第v个神经元到第j+1层的第u个神经的权重,例如下图中$\theta^{(1)}{23}$表示从第一层的第3个神经元到第二层的第2个神经元的权重,需要注意到的是下标uv是指v->u的权重而不是u->v,下图也给出了第一层到第二层的所有权重标注
- 一般地,如果第j层有$sj$个神经元(不包括bias神经元),第j+1层有$s{j+1}$个神经元(也不包括bias神经元),那么权重矩阵$\theta^{j}$的维度是$(s_{j+1}\times s_j+1)$
前向传播(Forward Propagration, FP)
后一层的神经元的值根据前一层神经元的值的改变而改变,以上图为例,第二层的神经元的更新方式为:
$$
a1^{(2)} = g(\theta{10}^{(1)}x0 + \theta{11}^{(1)}x1 + \theta{12}^{(1)}x2 + \theta{13}^{(1)}x_3)
$$
$$
a2^{(2)} = g(\theta{20}^{(1)}x0 + \theta{21}^{(1)}x1 + \theta{22}^{(1)}x2 + \theta{23}^{(1)}x_3)
$$
$$
a3^{(2)} = g(\theta{30}^{(1)}x0 + \theta{31}^{(1)}x1 + \theta{32}^{(1)}x2 + \theta{33}^{(1)}x_3)
$$
$$
a4^{(2)} = g(\theta{40}^{(1)}x0 + \theta{41}^{(1)}x1 + \theta{42}^{(1)}x2 + \theta{43}^{(1)}x_3)
$$
向量化实现(Vectorized Implementation)
如果我们以向量角度来看待上述的更新公式,定义:
$a^{(1)}=x=\left[ \begin{matrix}x_0\ x_1 \ x_2 \ x_3 \end{matrix} \right]$ $z^{(2)}=\left[ \begin{matrix}z_1^{(2)}\ z_1^{(2)} \ z1^{(2)}\end{matrix} \right]$ $\theta^{(1)}=\left[\begin{matrix}\theta^{(1)}{10}& \theta^{(1)}{11}& \theta^{(1)}{12}& \theta^{(1)}{13}\ \theta^{(1)}{20}& \theta^{(1)}{21}& \theta^{(1)}{22}& \theta^{(1)}{23}\ \theta^{(1)}{30}& \theta^{(1)}{31}& \theta^{(1)}{32} & \theta^{(1)}_{33}\end{matrix}\right]$
则更新公式可以简化为
$$
z^{(2)}=\theta^{(1)}a^{(1)}
$$
$$
a^{(2)}=g(z^{(2)})
$$
$$
z^{(3)}=\theta^{(2)}a^{(2)}
$$
$$
a^{(3)}=g(z^{(3)})=h_\theta(x)
$$
可以看到,我们由第一层的值,计算第二层的值;由第二层的值,计算第三层的值,得到预测的输出,计算的方式一层一层往前走的,这也是前向传播的名称由来。
神经网络与与逻辑回归的联系
逻辑回归是不含隐藏层的特殊神经网络,神经网络从某种程度上来说是对logistic回归的推广。
代价函数(含正则项)
在逻辑回归中只有一个输出,其代价函数为:
$$
J(\theta) = – \left[ \frac{1}{m} \sum{i = 1}^{m} \left( y^{(i)} log(h(x^{(i)})) + (1-y^{(i)}) log\left(1-h(x^{(i)})\right) \right) \right] + \frac{\lambda}{2m} \sum{j=1}^{n} \thetaj^2
$$
在神经网络中,有K个输出,所以其代价函数就相当于于L个逻辑回归问题的代价之和:
$$
J(\Theta) = -\frac{1}{m}\left[\sum\limits{i=1}^{m}\sum\limits{k=1}^{K}y^{(i)}{k}log(h_\theta(x^{(i)}))_k + (1-y^{(i)}k)log(1-(h\theta(x^{(i)}))k)\right] + \frac{\lambda}{2m}\sum{l=1}^{L-1}\sum\limits_{i=1}^{sl}\sum\limits{j=1}^{s{l+1}}(\Theta{ji}^{(l)})^2
$$
符号说明:
- $m$ — 训练example的数量
- $K$ — 最后一层(输出层)的神经元的个数,也等于分类数(分$K$类,$K≥3$)
- $y_k^{(i)}$ — 第$i$个训练exmaple的输出(长度为$K$个向量)的第$k$个分量值
- $(h_\theta(x^{(i)}))_k$ — 对第$i$个example用神经网络预测的输出(长度为$K$的向量)的第$k$个分量值
- $L$ — 神经网络总共的层数(包括输入层和输出层)
- $\Theta^{(l)}$ — 第$l$层到第$l+1$层的权重矩阵
- $s_l$ — 第$l$层神经元的个数, 注意$i$从1开始计数,bias神经元的权重不算在正则项内
- $s_{l+1}$ — 第$l+1$ 层神经元的个数
后向传播(Backpropagration, BP)
我们已经有了代价函数$J(\Theta)$,接下来我们需要利用梯度下降算法(或者其他高级优化算法)对$J(\Theta)$进行优化得到训练参数$\Theta$。
然而关键问题是,优化算法需要传递两个重要的参数:
- 代价函数$J(\Theta)$
- 代价函数的梯度$\frac{\partial J(\Theta)}{\partial \Theta}$
BP算法其实就是解决如何计算梯度的问题
例子以及推导因为太复杂,具体请点击这里
推导一遍!
梯度检验
这个方法是用数值计算的方法计算近似的梯度,再和反向传播算法中的梯度进行对比,若误差很小,则可以认为反向传播算法基本正确。
数值计算梯度的方法原理如下(双侧求导):
$$
\frac{\partial}{\partial \theta}(\theta) = lim_{\epsilon \to 0} \frac{J(\theta + \epsilon) – J(\theta – \epsilon)}{2\epsilon}
$$
当我们取$ϵ$很小的时候,例如$10^{−4}$,可以近似得到导数值。下面是计算对$\theta_1$梯度检验的例子
要注意这种数值计算的方法代价很大,因为每次计算一个参数的梯度都要调用两次代价函数。所以,在确定你的反向传播算法工作良好后,应该关闭梯度检验。
随机初始化
初始权重矩阵的初始化应该打破对称性 (symmetry breaking),避免使用全零矩阵进行初始化。可以采用随机数进行初始化,即
$$
\Theta^{(l)}_{ij} \in [-\epsilon, +\epsilon]
$$
如何训练一个神经网络
- 随机初始化权重矩阵
- 利用前向传播算法(FP)计算模型预测值$h_\theta(x)$
- 计算代价函数$J(\Theta)$
- 利用后向传播算法(BP)计算代价函数的梯度 $\frac{\partial J(\Theta)}{\partial \Theta^{(l)}}$
- 利用数值算法进行梯度检查(gradient checking),确保正确后关闭梯度检查
- 利用梯度下降(或者其他优化算法)求得最优参数$Θ$
支持向量机(SVM)
支持向量机(support vector machine,简称SVM),在处理一些复杂的非线性问题时相比逻辑回归和神经网络要更加简洁和强大,在工业界和学术界广泛应用。
假设
在逻辑回归中,代价函数为
$$
Cost(h(x), y) = -( y log(h(x)) + (1-y) log(1-h(x)) )
$$
$$
= – y log(\frac{1}{1 + e^{- \theta^T x}}) – (1-y) log(1-\frac{1}{1 + e^{- \theta^T x}})
$$

SVM中修改了一下代价函数
$$
Cost(h(x), y) = -( y cost_1(\theta^T x) + (1-y) cost_0(\theta^T x) )
$$
使之由两条直线构成(图中红色)

逻辑回归的假设为
$$
\min\limits\theta \frac{1}{m}\left[\sum\limits{i=1}^{m}y^{(i)}(-\log(h\theta(x^{(i)}))) + (1-y^{(i)})(-\log(1-h\theta(x^{(i)})))\right] + \frac{\lambda}{2m}\sum\limits{j=1}^{n}\theta{j}^2
$$
通过去掉$\frac{1}{m}$并且将$A+\lambda B$的形式变为$CA+B$的形式,可以得到SVM的假设为
$$
\min\limits\theta C\left[\sum\limits{i=1}^{m}y^{(i)}cost_1(\theta^Tx^{(i)}) + (1-y^{(i)})cost0(\theta^Tx^{(i)})\right] + \frac{1}{2}\sum\limits{j=1}^{n}\theta_{j}^2
$$
最大间隔(Large Margin Intuition)
由于$CA+B$要取最小值,当参数合适时,可以保证代价函数中前一部分代价为0,因此$A≈0$,从而SVM最大化间隔问题变为
$$
\begin{align}&\min\limits\theta\frac{1}{2}\sum\limits{j=1}^{n}\theta_j^{2}\ &s.t.\quad\begin{cases}\theta^{T}x^{(i)}\geq 1 \quad y^{(i)}=1\\theta^{T}x^{(i)}\leq -1 \quad y^{(i)}=0\end{cases}\end{align}
$$
由于CA+BCA+B要取最小值,因此A≈0A≈0,从而SVM最大化间隔问题变为

这里补充一下,支持向量指的是位于两条虚线上的点。
为什么叫向量?在高维空间中,每个点可以看作是从原点出发的向量,所以这些点也称为向量。
参数C相当于逻辑回归中的1/λ。
C 较大时,相当于λ较小,可能会导致过拟合(overfit),高方差(High variance)。
C 较小时,相当于λ较大,可能会导致欠拟合(underfit),高偏差(High bias)。

核函数
现实任务中,原始样本空间中可能不存在一个能正确划分两类样本的超平面。这时,可以将原始的低维空间映射到高维空间,找到一个合适的划分超平面。
$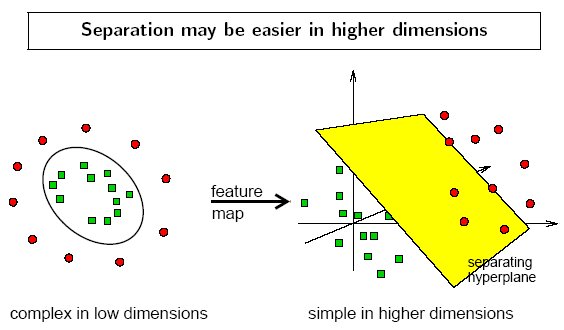
课中以高斯核为例子作为介绍
对于任意低维数据点$x$,定义它与低维空间中预先选定的标记点$l(i)$(landmarks)之间的相似性为
$$
f_i=similarity(x, l^{(i)})=exp\left(-\frac{||x-l^{(i)}||^2}{2\sigma^2}\right)
$$
这样当有$k$个landmarks时,我们将得到$k$个新的特征$f_i$,这样就将低维空间的点$x$投射为高维($k$维)空间中一个点。
如果$x$距离$l(i)$非常近,即$x≈l(i)$, 则相似性$f_i≈1$; 否则如果$x$距离$l^{(i)}$非常远,则相似性$f_i≈0$。
问题是如何选择landmarks?
一种做法是选择所有的m个样本点作为landmarks,这样对于具有n个特征的数据点$x(i)$,通过计算$f_i$,将得到一个具有m维空间的数据点$f^{(i)}$。
第二个问题是,如何得到参数$\theta$?
首先看上面没有用高斯核函数时的代价函数
$$
J(\theta) = C \left[ \sum_{i = 1}^{m} \left( y^{(i)} cost_1(\theta^T x^{(i)}) + (1-y^{(i)}) cost0(\theta^T x^{(i)}) \right) \right] + \frac{1}{2} \sum{j=1}^{n} \thetaj^2
$$
现在,需要把$\theta^T x^{(i)}$换成$\theta^T f^{(i)}$就可以了。由于$x$和$f$的维数不同,这里参数也不同啦。特别的,使用高斯核函数后,特征数和训练集实例数是一样多的。下面的n也可以换成m。
$$
J(\theta) = C \left[ \sum{i = 1}^{m} \left( y^{(i)} cost_1(\theta^T f^{(i)}) + (1-y^{(i)}) cost0(\theta^T f^{(i)}) \right) \right] + \frac{1}{2} \sum{j=1}^{n} \theta_j^2
$$
只要求出上面式子的最小值,就得到了参数$θ$。
总结:高斯核SVM参数对结果的影响
$C$较大时,相当于$λ$较小,可能会导致过拟合,高方差
$C$较小时,相当于$λ$较大,可能会导致欠拟合,高偏差
$σ$较大时,$f$变化更加平缓,这导致你的模型随着x的变化而缓慢变化,导致欠拟合,高偏差
$σ$较小时,$f$变化剧烈,导致过拟合,导致高方差
常见核函数
- 线性核(Linear kernel):不指定核时默认使用线性核。用于样本数m较小,特征数n较大时(思考一下,特征空间比较大,样本比较小时,可以很容易的找出一个平面作为划分)。
- 高斯核(Radial basis function kernel,RBF核):需要制定参数$\sigma^2$。用于样本数m中等(10-10000),特征数n较小(1-1000)时。注意,在使用前对数据进行feature scaling。
- 多项式核(Polynomal kernel)
- Sigmoid核
核函数的使用
当n较大时($n≥m$, n=10000, m = 1000),使用logistic回归或者SVM(with linear kernel)
当n较小,m中等时(n=10-1000, m = 10-100000),使用SVM(with Gaussian kernel)
当n较小, m较大时(n=1-1000, m = 500000),增加新的特征,然后适用logistic回归或者SVM(with linear kernel)
神经网络在各类n, m情况下都工作的很好,缺陷是训练速度比较慢。