
前言
这篇文章是我的吴恩达机器学习小结第二篇,主要总结非监督学习的部分,包括聚类,降维,异常检测
其它两篇链接如下:
另外,需要说明的是,由于博客暂时不能支持markdown的数学公式。暂时,你也可以选择在Github仓库中查看: )
K-means聚类
算法步骤
- 随机初始化$K$个聚类中心(cluster centroid) $\mu_1, \mu_2, \ldots, \mu_K$
- 类分配: 对于每个数据点$x^{(i)}$,寻找离它最近的聚类中心,将其归入该类;即$c^{(i)}=\min\limits_k||x^{(i)}-\mu_k||^2$,其中$c^{(i)}$表示$x^{(i)}$所在的类
- 移动类中心的位置: 更新聚类中心$u_k$的值为所有属于类$k$的数据点的平均值
- 重复2、3步直到收敛或者达到最大迭代次数

优化目标
用$\mu_{c^{(i)}}$表示第$i$个数据点$x^{(i)}$所在类的中心,则K-Means优化的代价函数为
$$
J(c^{(1)},\ldots,c^{(m)},\mu_1,\ldots,\muK)=\frac{1}{m}\sum\limits{i=1}^{m}||x^{(i)}-\mu{c^{(i)}}||^2
$$
希望找到最优参数使得该函数最小化,即
$$
\min\limits{\substack{c^{(1)},\ldots,c^{(m)} \ \mu_1,\ldots,\mu_K}}J(c^{(1)},\ldots,c^{(m)},\mu_1,\ldots,\mu_K)
$$
细节
1.怎么避免局部最优?
答:算法聚类的性能与初始聚类中心的选择有关,为避免陷入局部最优(如图2所示),应该运行多次(50次)取使得$J$最小的结果
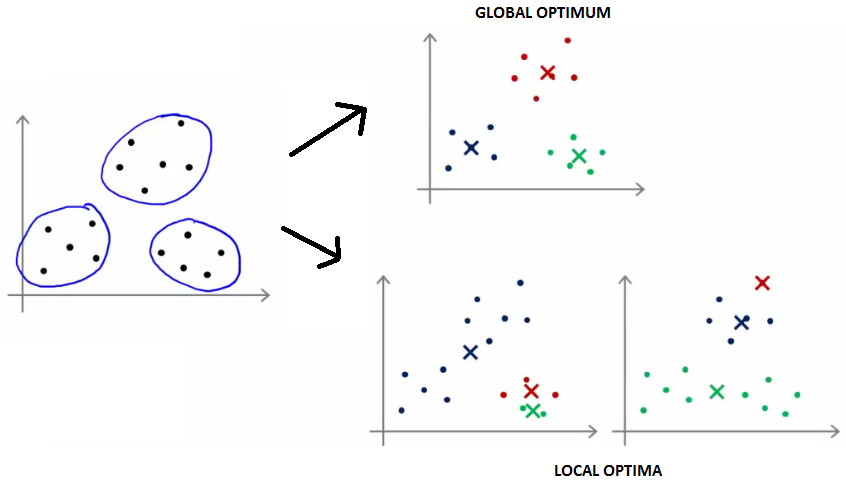
2.怎么确定类数量K的值?
Elbow方法,绘制$J$随$K$的变化曲线,选择下降速度突然变慢的转折点作为$K$值;对于转折不明显的曲线,可根据K-Means算法后续的目标进行选择。

PCA降维
算法步骤
数据预处理:
- 均值化(mean normalization):$\muj = \frac{1}{m}\sum\limits{i=1}^{m}x_j^{(i)}, x_j^{(i)}=x_j-\mu_j$
- 特征缩放(feature scaling):(可选,不同特征范围差距过大时需要) , $x_j^{(i)}=\frac{x^{(i)}-\mu_j}{\sigma_j}$
计算协方差矩阵(Convariance Matrix)
$$
\Sigma=\frac{1}{m}\sum\limits_{i=1}^{m}x^{(i)}(x^{(i)})^T \quad \text{or} \quad \Sigma = \frac{1}{m}X^TX
$$计算协方差矩阵$Σ$的特征向量$U$
选择$U$矩阵的前$k$个列向量作为$k$个主元方向,形成矩阵$U_{reduce}$
对于每个原始数据点$x(x\in R^n)$,其降维后的数据点$z(z \in R^k)$为$z=U_{reduce}^T x$
确定K值
重构数据:对于降维后$k$维数据点$z$,将其恢复$n$维后的近似点为$x{apporx}(\approx x)=U{reduce}z$
怎么确定k值?
平均均方误差:
$$
\frac{1}{m} \sum{i=1}^{m} || x^{(i)} – x{approx}^{(i)} ||^2
$$
训练集方差:
$$
\frac{1}{m} \sum{i=1}^{m} || x^{(i)}||^2
$$
选择最小的k值使得
$$
\frac{\frac{1}{m}\sum\limits{i=1}^{m}||x^{(i)}-x^{(i)}{approx}||^2}{\frac{1}{m}\sum\limits{i=1}^{m}||x^{(i)}||^2} \leq 0.01(0.05)
$$
在我的实践中,用到的是选择前k个特征值,使得这些值的和占总特征值和的比大于0.99。
应用PCA的建议
- 用于加速监督式学习:
- (1) 对于带标签的数据,去掉标签后进行PCA数据降维
- (2)使用降维后的数据进行模型训练
- (3) 对于新的数据点,先PCA降维得到降维后数据,带入模型获得预测值。
- 注:应仅用训练集数据进行PCA降维获取映射$x^{(i)}\rightarrow z^{(i)}$,然后将该映射(PCA选择的主元矩阵$x^{(i)}\rightarrow z^{(i)}$)应用到验证集和测试集
- 不要用PCA阻止过拟合,用正则化。
- 在使用PCA之前,先用原始数据进行模型训练,如果不行,再考虑使用PCA;而不要上来直接使用PCA。
异常检测
异常检测是一种非监督学习算法,用来发现不属于已知的一组数据的异常数据点。
给定数据集$x{(1)}, x{(2)}, …, x{(m)}$ ,假设这些已有数据是正常(normal)的。现在有一个新的数据$x{test}$ ,我们希望建立模型,来告诉我们这个新数据是正常还是异常的(anomalous)。
一般采用密度估计的方法:

红色是已有的正常数据点,根据它们的分布,蓝色圈越靠近中心,密度越大。越偏离中心,数据异常的可能也越大。表达式如下:
$$
\text{if} p(x) = \begin{cases}
\le \epsilon, & \text{anomaly} \
\epsilon, & \text{normal} \
\end{cases}
$$
异常检测的应用:
- 欺诈检测(Fraud detection)
- 制造业(Manufacturing)
- 数据中心监视电脑(Monitering computers in data center)
算法步骤
对于训练数据集${x^{(1)}, x^{(2)}, \ldots, x^{(m)}}$,其中数据点$x^{(i)}\in R^n$并假设每个特征均服从高斯分布,即$x^{(i)}_j \sim N(\mu, \sigma^2)$,可如下建立模型$p(x)$
$$
\begin{align}p(x)&=p(x_1; \mu_1, \sigma_1^2)p(x_2; \mu_2, \sigma_2^2)\ldots p(x_n; \mu_n, \sigman^2) \ &= \prod\limits{j=1}^n p(x_j; \mu_j, \sigma_j^2)\end{align}
$$
算法步骤:
- 特征选择:选择能够指示异常行为的特征
- 参数估计:用训练数据集估计每个特征的整体均值$\mu_j$和方差$\sigma_j^2$,即$\muj = \frac{1}{m}\sum\limits{i=1}^{m}x^{(i)}_j$,$\sigma^2j=\frac{1}{m}\sum\limits{i=1}^{m}(x^{(i)}_j-\mu_j)^2$
- 这里需要注意的是,在统计学中,$\sigma^2$的系数为$\frac{1}{m-1}$,而在机器学习中习惯使用$\frac{1}{m-1}$,机器学习中要求没有那么精确
- 用估计得到的参数$\mu_1, \mu_2, \ldots, \mu_n$,$\sigma^2_1, \sigma^2_2, \ldots, \sigma^2_n$建立模型$p(x)$
- 对于给定新的数据点$x{new}$, 计算$p(x{new})$;如果$p(x_{new})<\epsilon$则发生异常,否则正常。
算法细节
我们在实现异常检测算法时,有两个问题:
- 如何划分样本集?
- 如何选择阈值$ϵ$的值?
举个栗子,有10000个正常数据,20个异常数据。可以如下划分:
- 6000个正常数据作为训练集
- 2000个正常数据和10个异常数据作为交叉检验集
- 2000个正常数据和10个异常数据作为测试集
根据训练集可以得到高斯分布的参数,然后根据交叉检验集运行函数,并得到结果。根据查准率、查全率或F1-score来选择阈值$ϵ$的值。
最后选出阈值后,在测试集上运行,计算系统的查准率、查全率和F1-score。
和监督学习方法的对比
| 异常检测 | 监督学习 |
|---|---|
| 数据中正常数据y=0很多异常数据y=1很少 | 数据中y=0和y=1的数据都很多 |
| 异常的种类很多,有限的样本不能获得异常的全部特征 | 有足够多的样本用于训练 |
| 未来的异常可能和已有的异常不同 | 未来的异常和已有的异常数据特征相似 |
| 例子:1. 欺诈行为检测2. 飞机引擎是否故障3. 数据中心计算机是否正常 | 例子1. 垃圾邮件判定2. 天气预报3. 肿瘤分类 |
特征选择
选择的特征需要近似服从于高斯分布,如果明显不服从高斯分布,可以做适当的转换,例如$log(x), log(x+c), \sqrt{x}, x^{1/3}$等。

另外,上述模型仅当特征AB相互独立时才有$P(AB)=P(A)P(B)$。
当各个特征之间存在依赖时,一元高斯模型不能很好的刻画$p(x)$,需要使用多元高斯模型。
多元高斯模型$p(x)$的建立不再是各个概率相乘,而直接用多元高斯分布进行刻画
$$
p(x;\mu, \Sigma)=\frac{1}{(2\pi)^{n/2}|\Sigma|^{1/2}}\exp\left(-\frac{1}{2}(x-\mu)^T\Sigma^{-1}(x-\mu)\right)
$$
例如下图中,如果x1和x2单独分开来看,左上方绿色的点都不属于异常。但是如果x1和x2一起看,相比红色的点,就属于异常了。
