
前言
这篇文章是我的吴恩达机器学习小结第三篇,主要总结机器学习应用建议、机器学习系统设计、大规模机器学习部分。
其它两篇链接如下:
另外,需要说明的是,由于博客暂时不能支持markdown的数学公式。暂时,你也可以选择在Github仓库中查看: )
机器学习应用建议
模型选择
一般来讲,把数据分成三个部分:
- 60%数据用作训练集(Training set)
- 20%数据用作交叉验证集(Cross ValidaDon set, CV set)
- 20%数据用作测试集(Test set)
训练集的数据用于训练算法得到模型(多个不同的模型),交叉验证集的数据可以用来选择合适的模型(选一个误差最小的),测试集的数据用来评估推广后该模型的准确度。
偏差和方差
高偏差(High bias)基本上就是欠拟合,而高方差(High variance)就是过拟合的问题。
高偏差时,Test和CV上的结果误差都会很大,而高方差时,Test上的误差很小,但CV上的误差很大

对于含有regularization的模型,参数$λ$的不当选择也会导致模型出现欠拟合和过拟合。以线性回归为例,如果$λ$选择过大,那么模型会出现欠拟合;反之如果$λ$过小,则容易出现过拟合。
解决办法是:通过将数据集划分为训练集/验证集/测试集,然后$λ$取一系列值(0, 0.01, 0.02, 0.04, 0.08…), 对于每一个$λ$取值用训练集训练参数$θ$,对于得到的每一个模型,在验证集选择使得错误最小的参数$λ$作为模型参数,即$J_{cv}(\theta)$最小。
更直观的方式,可以做出$J{train}(\theta)$和$J{cv}(\theta)$随$λ$的变化曲线,选择最优的$λ$。

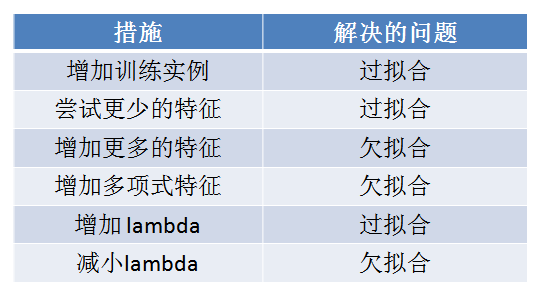
学习曲线
学习曲线是$J{train}(\theta)$和$J{cv}(\theta)$随训练集尺寸的变化曲线,可以用于识别欠拟合和过拟合问题。
对于欠拟合,由于模型过于简单,因而训练错误$J{train}(\theta)$和验证错误$J{cv}(\theta)$均较大,增加训练实例并不能改善这种情况
对于过拟合问题,在训练错误$J{train}(\theta)$非常小而验证错误$J{cv}(\theta)$很大,两者之间有一个非常大的鸿沟(gap),在这种情况下下增加训练实例很有可能改善算法性能。

总结
机器学习系统设计
构建一个机器学习系统的方法
构建一个学习算法的推荐方法为:
- 从一个简单的能快速实现的算法开始,实现该算法并用交叉验证集数据测试这个算法
- 绘制学习曲线,决定是增加更多数据,或者添加更多特征,还是其他选择
- 进行误差分析:人工检查交叉验证集中我们算法中产生预测误差的实例,看看这些实例是否有某种系统化的趋势
思考怎样能改进分类器。例如,发现是否缺少某些特征,记下这些特征出现的次数。
处理偏斜数据(skewed data)
例子:对于癌症/非癌症的分类问题,假设y=1表示癌症,y=0表示非癌症,因为癌症的人数必然是少数(不妨假设为1%),那么一个非常naive的算法可以在任何情况下直接返回0,这样表面上该算法的正确率高达99%(因为本来99%的人都是非癌症),然而实际上容易看出,对于癌症患者该算法一个也没有检测出来。如癌症类这样相较于其他类本身的比例与其他类数量差距巨大的类称为偏斜类(skewed class)。为了更好的衡量算法在偏斜数据集上的效果,仅仅使用准确率是不够。
为此引入了查准率(Precision)和查全率(Recall)的概念。
| 实际为1 | 实际为0 | |
|---|---|---|
| 预测为1 | 正确肯定(True Positive,TP) | 错误肯定(False Positive,FP) |
| 预测为0 | 正确否定(True Negative,TN) | 错误否定(False Negative,FN) |
$$
\text{Precision(查准率)} = \frac{\text{True positive}}{\text{Predict positive}} = \frac{\text{True positive}}{\text{True positive} + \text{False positive}}
$$
$$
\text{Recall(查全率)} = \frac{\text{True positive}}{\text{Actual positive}} = \frac{\text{True positive}}{\text{True positive} + \text{False negative}}
$$
一般情况下,两者不可兼得

为了两者之前取得平衡,定义了F1
$$
F_1 = \frac{2 \times \text{Precision} \times \text{Recall}}{\text{Precision}+\text{Recall}}
$$
F1值越高越好。
使用大数据集(large data set)
Q:什么时候应该去获取更多数据,而不是改进算法呢?
A:模型具有足够多的特征来预测y值从而避免欠拟合。
这时,可以在大数据集上进行训练从而避免过拟合(当数据足够多时,模型不太可能出现过拟合)。
大规模机器学习
当训练集的规模很大时,可以帮助我们训练出更好的结果。但是,训练集规模的增大也带来了计算的代价非常大。
可以通过绘制学习曲线来判断大规模的训练集是否有必要。

分析:作图的训练误差很小,但是CV误差很大,说明已经过拟合,这个时候增大训练集可以使模型避免过拟合;对于右图,训练误差和CV误差差不多大,单纯的增加训练集已经不能使误差减小,这个时候可以增加训练的特征,再增加训练集训练。
梯度下降
批梯度下降 (Batch Gradient Descent)
以线性回归为例,用梯度下降算法进行参数更新的公式为
$$
\theta_j=\thetaj-\alpha\frac{1}{m}\sum\limits{i=1}^{m}(h_\theta(x^{(i)})-y^{(i)})x_j^{(i)}
$$
可以看到每次参数更新一次,都需要将整个训练集扫描一遍,所以称为批梯度下降,这种更新方式对于参数集很大的集合(例如m=100,000,000)运行速度十分慢,为了加快算法运行速度,提出了随机梯度下降。
随机梯度下降 (Stochastic Gradient Descent)
每次仅用一个example来更新参数$θ$,仍以线性回归为例,随机梯度下降算法为
随机重排列整个训练集(shuffle)
重复下列过程多次(数据集较大时可以重复1~10次):
for i = 1, …, m {
$$
\theta_j := \thetaj – \alpha (h{\theta}(x^{(i)}) – y^{(i)}) x_j^{(i)}
$$
}
小批梯度下降 (Mini-Batch Gradient Descent)
随机梯度下降只用1个样本进行参数更新,而Mini梯度下降使用b(1<b<m)个样本进行参数更新。
仍以线性回归为例,假如我们有m=1000个样本,我们可以用每b=10个样本进行参数更新
$$
\theta_j=\thetaj-\alpha\frac{1}{10}\sum\limits{k=i}^{i+9}(h_\theta(x^{(k)})-y^{(k)})x_j^{(k)}
$$
算法收敛性
怎么判断梯度下降是否在收敛呢?怎么选择学习率α?
批梯度处理能够保证算法收敛到最小值(如果选择的学习速率α合适的话),可以plot代价函数J(θ)随迭代次数的曲线,如果曲线是总是下降的,则能够收敛,反之需要调整学习速率。
在随机梯度下降中,每次更新参数前计算代价cost,但画图时,一般选X次迭代的代价平均值。这样可以得到X次迭代的代价均值和X次迭代的次数的图形:
如果曲线的趋势是下降的,可以判定是正在收敛。
如果趋势不是下降的,可能需要:
调整增大或者减小平均的example数(将100改为1000或者10等)
减小学习率,可以令学习率随着迭代次数增加而减小。例如
$$
\alpha = \frac{\text{const1}}{\text{iterationNumber + const2}}
$$
在线学习(Online Learning)
之前的算法都是有一个固定的训练集来训练模型,当模型训练好后对未来的样本进行分类、回归等。
在线学习则不同,它对每个新来的样本进行模型参数更新,因此没有固定的训练集,参数更新的方式则是采用随机梯度下降。
在线学习的优势是模型参数可以随用户的偏好自适应的进行调整。
以logistic回归为例,在线学习方式如下:
Repeat forever {
1. 获取当前example (x, y)
2. 使用(x,y)进行参数更新:$\theta_j=\theta_j-\alpha(h_\theta(x)-y)x_j$
}
映射化简(Map Reduce)
数据量很大时,有必要把数据分配给多个计算机计算,最后把各个结果汇总。这叫做映射化简。
例如需要对400个训练实例求和,可以分配4台机器,每台计算100个数据。最后把4个结果合并。